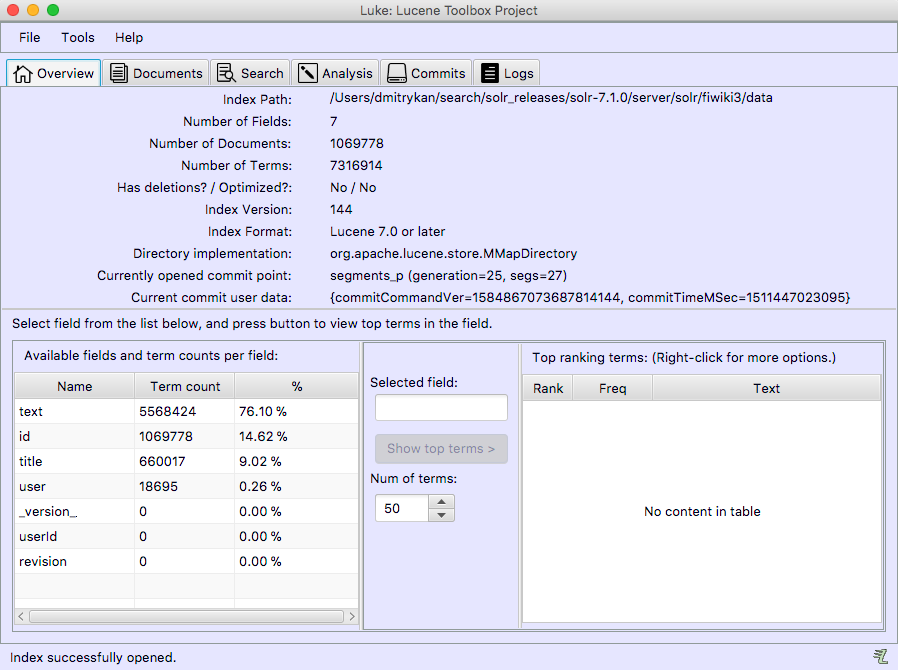
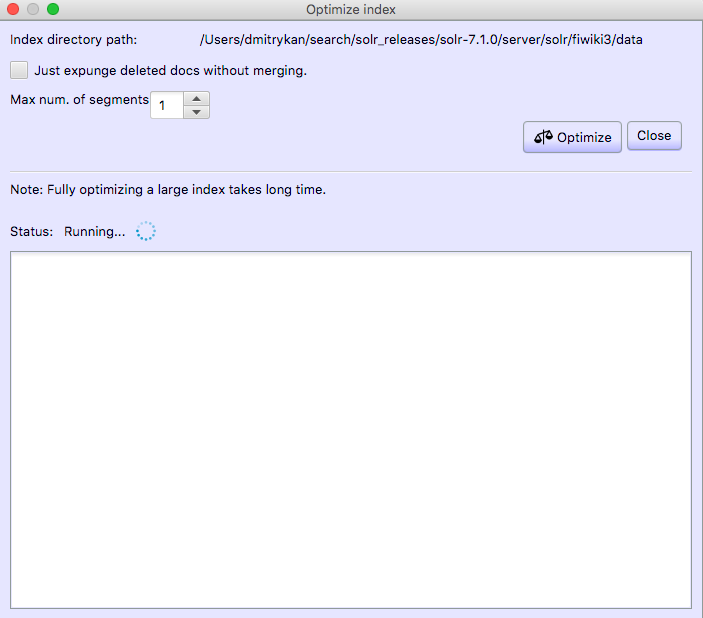
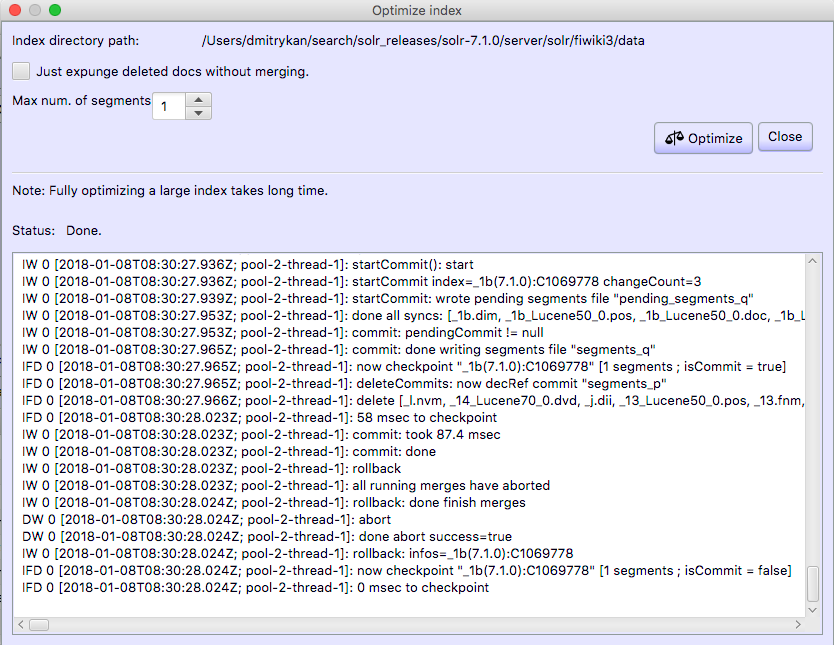
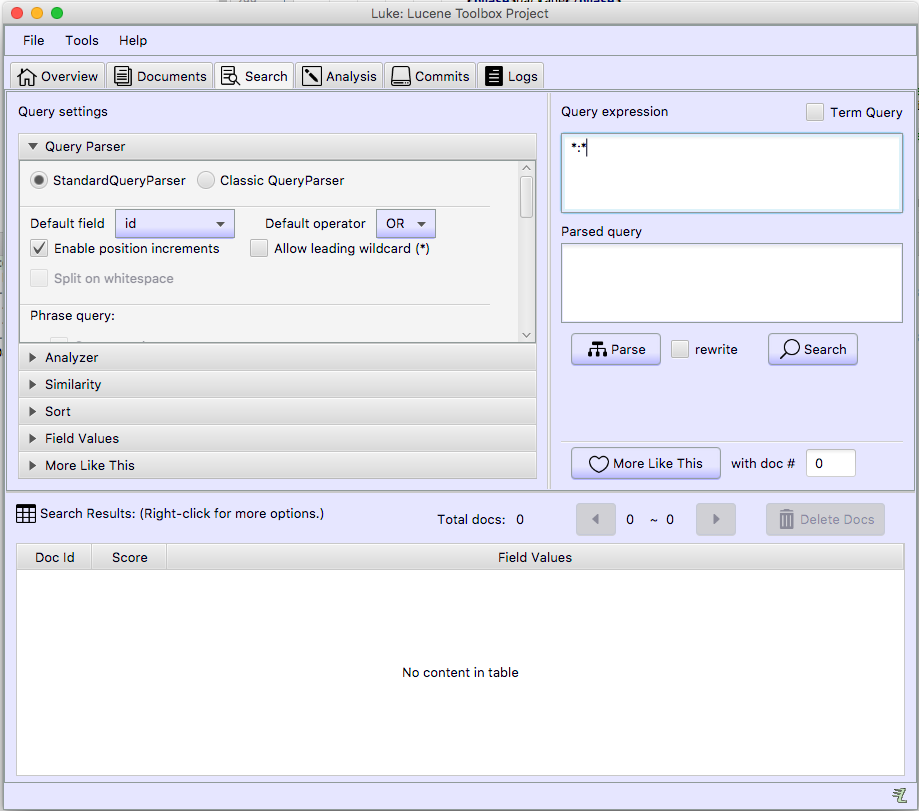
As Christmas and New Year holidays are coming up, I wanted to reflect on two conferences in two different countries -- Estonia and Ukraine, that I had a pleasure to participate and / or organize this year.
AINL
AINL Conference (https://ainlconf.ru/2019/program), held in Tartu in November, focused a lot on applying deep learning to NLProc, with two tutorials by Dmitry Ustalov (Yandex) on Crowdsourcing on Language Resources and Evaluation and by Andrey Kutuzov (University of Oslo) on Diachronic Word Embeddings for Semantic Shifts Modelling. Andrey Kutuzov's tutorial was practical and involved some Python coding, resulting in a pull request: https://github.com/wadimiusz/diachrony_for_russian/pull/5 that I submitted for the task of comparing semantic shifts in meaning between Soviet and Post Soviet eras. This code uses Jaccard similarity as a local method for detecting shifts in meaning. There are also global methods, like Procrustes alignment, the only downside of which is it is slower, than Jaccard. You can read more detail on the task in Andrey's AINL slides.
 |
| Credit: Dmitry Kan |
In terms of submitted papers -- the review process was double-blind and involved at least 3 reviewers per paper. The result was 30% acceptance rate and 12 out of 40 papers that did make it, focused on data acquisition and annotation, human-computer interaction, statistical NLProc (including paper by Ansis Bērziņš on usage of speech recognition for determining language similarity -- video) and neural language models (one of the works for morpheme segmentation using Bi-LSTM model cited the work of Mathias Creutz with whom we worked at AlphaSense 2010-2016).
Last day of the conference focused on the industrial applications of AI in NLProc. By invitation of Lidia Pivovarova (University of Helsinki) I presented on the search engine and NLProc work we've done at AlphaSense, including smart synonyms, sentiment analysis, named entity recognition and salience resolution, theme modelling and high-precision search.
One of the challenges for the industrial presentation was that it had to last for 1,5 hours. If you consider your audience ability to focus only for 40 minutes, you have got to do something else than 65 slides. I decided to make about 30 slides and then handle the rest of my talk with Q&A. The outcome has been very surprising to myself, because the audience did want to learn details of AlphaSense product, making the Q&A last for 50 minutes. Quite a few questions I managed to answer with the product itself -- this sparks genuine interest in understanding the UI of an AI product powering the financial industry. I hope this was beneficial for the audience to dive into the workflows of financial knowledge workers and how NLProc can help solve their daily routine tasks better.
Customer Development Marathon
Customer development is the topic that interests me from the point of the product development. Just recently I've learnt about jobs-to-be-done approach to mining for real jobs that your customers hire your product for. One example with which Clayton Christensen of Harvard Business School motivates this approach is the job that male consumers of milkshakes had on the their way to work every day: stay engaged in life during monotonous driving and stay full until 10 a.m.
The conference (or marathon as we called it) on customer development attracted 70 participants at iHUB co-working center in Kyiv, Ukraine. Speakers from various established companies -- YouScan, MacPaw, PromoRepublic, Competera, AlphaSense, Kyivstar, Terrasoft, PMLab, Portmone.com, Weblium, VARUS, SendPulse, EVO.company -- presented 5 min talks about specific cases on engaging with their customers to grow conversion, retention and happiness with their products. Following the presentations, the discussion panels dug deeper into how to implement a customer-centric business.
 |
| Credit: Maria Kudinova |
We've organized the marathon in 3 panels:
- Idea. Analysis. Validation
- Creation. Delivery. Launch and
- Sales. Feedback. Innovation.
Each of these panels focused on a particular stage of product development from idea to post-sale feedback and innovation loop. The audience learnt about how to conduct an efficient user interview, what tools help reach out to new or existing clients, how not to push your product into consulting or outsource, how to establish an internal company-wide communication to stay on the same page when shaping the product, marketing and sales around customer needs.
Both events were full of networking, meeting new and familiar faces in the industry and academia and learning a lot. For anything you aspire to build next year, focusing on real value and ease of use of your NLP / AI / search products, and thinking what job your users hire your products for will help you serve them better.